概要
本記事は Qiita Kubernetes Advent Calendar 2020 その2 の第7日目の記事となります。
qiita.com
CNCFのSandbox Projectsの1つであるKEDA(Kubernetes-based Event Driven Autoscaling) というオートスケーラーについて、公式ページの内容を整理して紹介します。
www.cncf.io
KEDAについて
KEDAとはKubernetes-based Event Driven Autoscalingの頭文字をとったもので、文字通りKubernetesベースのイベントドリブンオートスケーラーとなります。
KEDAによって、処理する必要がある様々なイベントをトリガーにしてKubernetesでのpodのスケールが可能です。
KEDAはユーザーのKubernetesクラスターで追加できるシンプルで、軽量なコンポーネントです。
KEDAはHPAのようなKubernetesの標準コンポーネントとともに動作し、コンポーネントの上書きや重複無しに機能を拡張できます。
KEDAによって、他のアプリケーションを機能させたまま、イベントドリブンのスケールを使いたいアプリケーションを明示的にマッピングできます。これにより、KEDAは他のいくつかのKubernetesアプリケーションやフレームワークと一緒に実行することができ、柔軟で安全なオプションとなっています。
KEDAはどのように動作するか
KEDAはKubernetesクラスター内で下記の2つの役割を担います。
エージェント: KEDAはKubernetesのDeploymentを有効・無効を切り替えることでスケールさせたり、イベントがない場合はレプリカ数を0にスケールインさせます。これはKEDAをインストールしたときに稼働する
keda-operatorコンテナーの主要な役割の一つです。メトリクス: KEDAはKubernetesのメトリクスサーバーとして機能し、キューの長さややストリームラグなどのリッチイベントデータをHorizontal Pod Autoscalerに公開してスケールアウトを促進します。 ソースから直接イベントを消費するのはDeploymentに任されます。KEDAはリッチイベントの統合の保持や、イベントの完了やキューメッセージの停止などのジェスチャーを有効にします。 このメトリクスの提供は、KEDAをインストールした時に稼働する
keda-operator-metrics-apiserverコンテナーの主要な役割です。
KEDAのアーキテクチャ
公式ページからの参照ですが、下記のKEDAのダイアグラム図はKEDAがKubernetes HPA、外部のイベントソース、Kubernetesの etcdデータストアとどのように協調するかを示したものです。
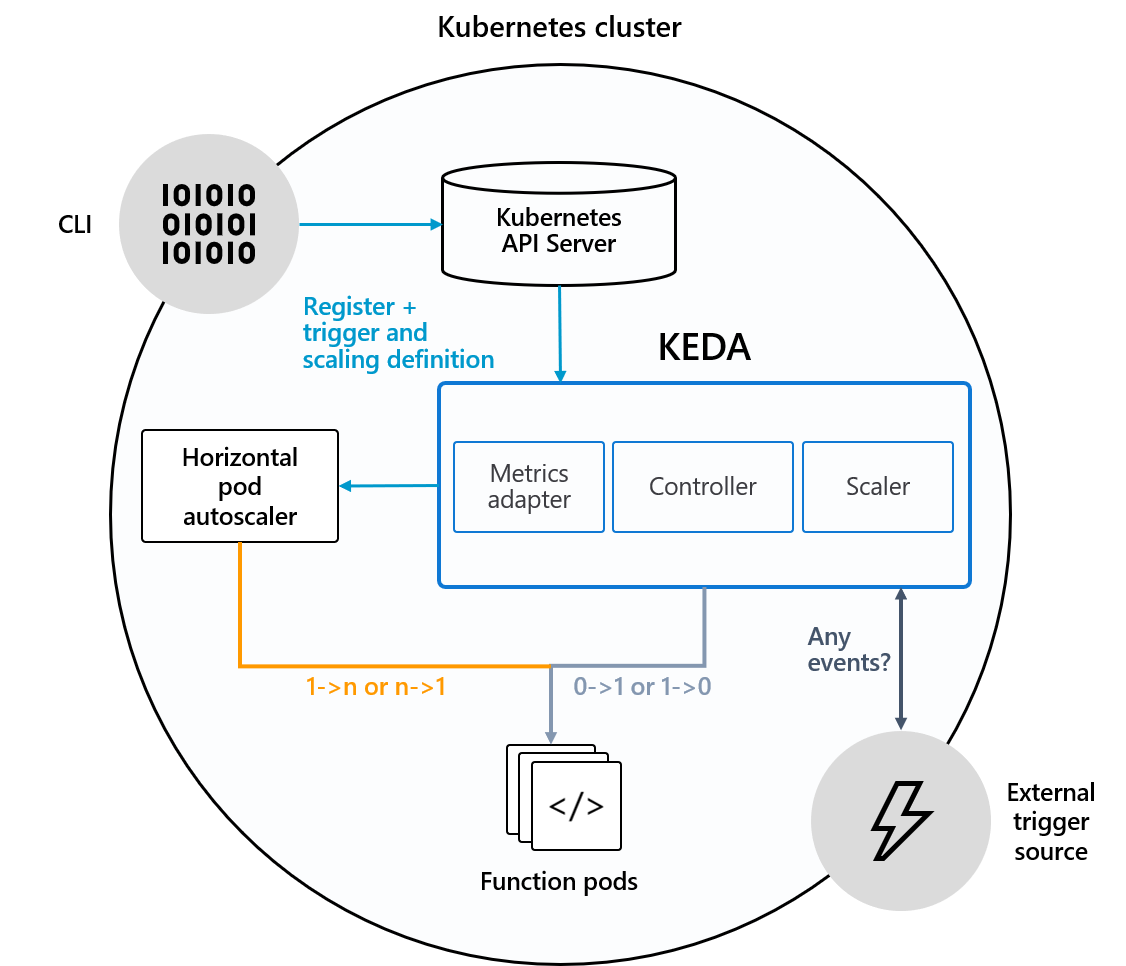
この図からわかるように、KEDAのリソースが、外部のトリガーソースから何らかのイベントを検知し、HPAを操作して該当のDeploymentやStatefulSetなどのリソースをスケールイン・アウトさせます。
イベントソースとスケーラー
KEDAは幅広い種類のスケーラーをもっており、それぞれDeploymentが有効または無効になるべきかを判定し、特定のイベントソース用にカスタムメトリクスを提供します。
スケーラーは下記のようなものが利用できます。 - CPU KEDA | CPU - Cron KEDA | Cron - Memory KEDA | Memory
他にもRabbitMQ Queueや Redis Streamsなど、現時点で様々なスケーラーが利用できます。 keda.sh
カスタムリソース(CRD)
KEDAをインストールした際、下記の3つのカスタムリソースが作成されます。
1. scaledobjects.keda.sh
2. scaledjobs.keda.sh
3. triggerauthentications.keda.sh
これらのカスタムリソースは、イベントソース(とそのイベントソースに対する認証)をDeployment、StatefulSet、Custom Resource、Jobにたいしてマッピングします。
ScaledObjects: は、イベントソース(例: Rabbit MQ)と/scaleというサブリソースを定義したDeployment、StatefulSet、Custom Resourceとのマッピングの理想状態を表します。ScaledJobsは、イベントソースとJobとのマッピングを表します。- 上記2つは、イベントソースのモニタリングのために認証の設定とSecretsを保持する
TriggerAuthenticationを参照することがあります。
KEDAを使ってみる
KEDAのデプロイ
ここではHelmを使って kedaというネームスペースを作ってそこにkedaのhelm chartsをインストールすることによってKEDAをデプロイさせます
Helmを使った方法
1.Helm repoの追加
helm repo add コマンドでレポジトリーを追加し、helm repo listでレポジトリーが登録されたことを確認します。
➜ ~ helm repo add kedacore https://kedacore.github.io/charts "kedacore" has been added to your repositories ➜ ~ helm repo list NAME URL kedacore https://kedacore.github.io/charts
2.Helm repoの更新
➜ ~ helm repo update Hang tight while we grab the latest from your chart repositories... ...Successfully got an update from the "kedacore" chart repository Update Complete. ⎈Happy Helming!⎈
- kedaというHelm chartのインストール まずKubernetesクラスター上にkedaというNamespaceを追加します。 kedaというNamespace上でchartをインストールします。
➜ ~ kubectl create namespace keda namespace/keda created ➜ ~ kubectl get namespace NAME STATUS AGE default Active 35m keda Active 3s kube-node-lease Active 35m kube-public Active 35m kube-system Active 35m
helm install [NAME] [CHART] [flags]
インストール完了後、Kubernetesクラスターのkeda Namespace上に、前述した keda-operator-metrics-apiserverとkeda-operatorというDeploymentと、それによって作られるReplicaSetおよびPod、そしてkeda-operator-metrics-apiserverというClusterIP Serviceが作成されていることが確認できます。
➜ ~ kubectl get all -n keda NAME READY STATUS RESTARTS AGE pod/keda-operator-8488964969-6cf9w 0/1 Running 0 24s pod/keda-operator-metrics-apiserver-5b488bc7f6-xwtvj 0/1 Running 0 24s NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE service/keda-operator-metrics-apiserver ClusterIP 10.98.228.180 <none> 443/TCP,80/TCP 24s NAME READY UP-TO-DATE AVAILABLE AGE deployment.apps/keda-operator 0/1 1 0 24s deployment.apps/keda-operator-metrics-apiserver 0/1 1 0 24s NAME DESIRED CURRENT READY AGE replicaset.apps/keda-operator-8488964969 1 1 0 24s replicaset.apps/keda-operator-metrics-apiserver-5b488bc7f6 1 1 0 24s
これでKubernetesクラスターにKEDAのService、Deploymentリソースの作成ができました。
ここから、実際にKEDAを使ったpodのスケーリングの例を取り上げます。
今回は下記の2つによるスケーリングを試してみます。
- RabbitMQ
- Cron
例1: RabbitMQのスケーリング
RabbitMQのキューの数を元にスケーリングさせるためのサンプルが公式で用意されているので、それを元に下記の手順で動作を確認します。
- RabbitMQのリソースをhelmで作成
- RabbitMQのキューに送られたデータを処理するrabbitmq-consumerと、KEDAのRabbitMQ用トリガーリソースを作成する
- 上記のRabbitMQのキューに対してデータを送信し、rabbitmq-consumerがスケールするのを確認する
github.com
ここでは、helm v3系がインストールされている前提で、rabbitmqのhelm chartをインストールしていきます。
https://github.com/kedacore/sample-go-rabbitmq#creating-a-rabbitmq-queue
まずはrabbitmq用のchartがあるレポジトリがhttps://charts.bitnami.com/bitnamiとなるため、レポジトリを追加します。
helm repo add bitnami https://charts.bitnami.com/bitnami
レポジトリ追加後、rabbitmq chartをインストールします。 ここでは、サンプルの通り、インストール時に認証用のusername passwordを指定します。
helm install rabbitmq --set auth.username=user --set auth.password=PASSWORD bitnami/rabbitmq
これでRabbitMQ関連のKubernetesリソースをhelm chartによってインストールできました。
- RabbitMQ consumerのデプロイ
次に、RabbitMQのキューに送られたデータを処理するrabbitmq-consumerと、KEDAのRabbitMQ用トリガーリソースを作成します。
公式のサンプルに、関連するリソースをまとめたマニフェストファイルがあるので、それを使ってkubectl applyでリソースを作成します。
https://github.com/kedacore/sample-go-rabbitmq#deploying-a-rabbitmq-consumer
➜ sample-go-rabbitmq git:(main) kubectl apply -f deploy/deploy-consumer.yaml secret/rabbitmq-consumer-secret created deployment.apps/rabbitmq-consumer created scaledobject.keda.sh/rabbitmq-consumer created triggerauthentication.keda.sh/rabbitmq-consumer-trigger created ➜ sample-go-rabbitmq git:(main) kubectl get deploy NAME READY UP-TO-DATE AVAILABLE AGE rabbitmq-consumer 1/1 1 1 6s
deploy-consumer.yamlには、下記の4つのリソースに関するマニフェストが記述されています。
https://github.com/kedacore/sample-go-rabbitmq/blob/main/deploy/deploy-consumer.yaml
- Secret rabbitmq-consumer-secret
- Deployment rabbitmq-consumer replicas指定無しのため、1
- ScaledObject rabbitmq-consumer spec.scaleTargetRef: name: rabbitmq-consumer これでターゲットとなるDeployment名を指定
- TriggerAuthentication Secret rabbitmq-consumer-secretを指定
Deploymentがキューのデータを処理するconsumerで、 KEDAのRabbitMQトリガー用のリソースがScaledObject, TriggerAuthentication, Secretとなります。
このマニフェストの反映により、HPAもできているのが確認できます。
➜ sample-go-rabbitmq git:(main) kubectl get hpa NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE keda-hpa-rabbitmq-consumer Deployment/rabbitmq-consumer 243/5 (avg) 1 30 1 2m3s ➜ sample-go-rabbitmq git:(main) kubectl describe hpa keda-hpa-rabbitmq-consumer Name: keda-hpa-rabbitmq-consumer Namespace: default Labels: app.kubernetes.io/managed-by=keda-operator app.kubernetes.io/name=keda-hpa-rabbitmq-consumer app.kubernetes.io/part-of=rabbitmq-consumer app.kubernetes.io/version=2.0.0 scaledObjectName=rabbitmq-consumer Annotations: <none> CreationTimestamp: Fri, 11 Dec 2020 01:28:08 +0900 Reference: Deployment/rabbitmq-consumer Metrics: ( current / target ) "rabbitmq-hello" (target average value): <unknown> / 5 Min replicas: 1 Max replicas: 30 Deployment pods: 0 current / 0 desired Conditions: Type Status Reason Message ---- ------ ------ ------- AbleToScale True SucceededGetScale the HPA controller was able to get the target's current scale ScalingActive False ScalingDisabled scaling is disabled since the replica count of the target is zero ScalingLimited True ScaleUpLimit the desired replica count is increasing faster than the maximum scale rate Events:
このHPAリソースが何によって作成されるか気になったので、KEDAのソースを確認したところ、どうやらScaledObjectのControllerのReconcile loopの処理によって作成されているようです。
https://github.com/kedacore/keda/blob/7ec8077fc3e9430a1f8442444de87540a5e61d7e/controllers/scaledobject_controller.go#L177
Reconcile loopの処理で、ScaledObjectReconciler.ensureHPAForScaledObjectExistsを実行し、毎回該当するHPAリソースが存在するか確認し、存在しなければ新規のHPAを作成しています。 https://github.com/kedacore/keda/blob/7ec8077fc3e9430a1f8442444de87540a5e61d7e/controllers/scaledobject_controller.go#L274-L287
これでRabbitMQのメッセージの受け取りの準備ができました。
キューに対してメッセージをパブリッシュする
次に、先ほど作成したRabbitMQのキューに対してメッセージをパブリッシュするためのJobを作成します。
下記のJobは、helloキューに対して300メッセージをパブリッシュするものです。 このJobも公式のサンプルレポジトリに存在するので、それを使ってkubectl applyを実行してリソースを作成します。 sample-go-rabbitmq/deploy-publisher-job.yaml at 0eb426ea875239feb2b3158a2406251ca20d3ab8 · kedacore/sample-go-rabbitmq · GitHub
kubectl apply -f deploy/deploy-publisher-job.yaml
このあとJobが実行され、kubectl get -w でDeploymentの変更をwatchして、rabbitmq-consumerがスケールされているのを確認できます。
➜ sample-go-rabbitmq git:(main) kubectl get deploy -w NAME READY UP-TO-DATE AVAILABLE AGE rabbitmq-consumer 0/0 0 0 11m rabbitmq-consumer 0/1 0 0 12m rabbitmq-consumer 0/1 0 0 12m rabbitmq-consumer 0/1 0 0 12m rabbitmq-consumer 0/1 1 0 12m rabbitmq-consumer 1/1 1 1 12m rabbitmq-consumer 1/4 1 1 13m rabbitmq-consumer 1/4 1 1 13m rabbitmq-consumer 1/4 1 1 13m rabbitmq-consumer 1/4 3 1 13m rabbitmq-consumer 1/4 4 1 13m rabbitmq-consumer 2/4 4 2 13m rabbitmq-consumer 3/4 4 3 13m rabbitmq-consumer 4/4 4 4 14m
上記のように、徐々にDeploymentのreplicasが増えていくのが分かります。
キューが空になって、指定されたクールダウンピリオドがたったあと、レプリカ数がゼロにスケールインします。 これで、rabbitMQのキューの長さが一定以上になるとスケールアウトし、キューの処理が完了すると徐々にスケールインすることを確認できました。
例2: Cronスケジューラーによる指定期間中のスケール
続いて、KEDAのCronスケジューラーによる指定期間でのスケールをさせてみます。 KEDA | Cron
ここでは、先ほどの例1で作成したrabbitmq-consumer Deploymentをスケール対象とし、日本時間で毎時0分から15分の15分間pod数10へスケールアウトを行うためのScaledObjectの設定を記述します。
注意として、あくまで開始時間(この例では毎時0分)にスケールを開始するため、指定したpod数に達するのは毎時0分ちょうどではありません。
設定方法は上記のCronスケーラーの公式ドキュメントを参照してください。
Cron用のScaledObject作成の前に、先ほど作成したRabbitMQ用のScaledObjectを削除しておきます。
# ScaledObject rabbitmq-consumerを削除 $ kubectl delete so rabbitmq-consumer scaledobject.keda.sh "rabbitmq-consumer" deleted
Cron用のScaledObject用のマニフェストファイルを作成します。 この例では rabbitmq-cron-scale-object.yaml というファイル名にします。
apiVersion: keda.sh/v1alpha1 kind: ScaledObject metadata: name: rabbitmq-consumer-cron # cronによるrabbitmqスケーラー namespace: default spec: scaleTargetRef: name: rabbitmq-consumer # スケール対象のリソース名(Deployment: rabbitmq-consumer) triggers: - type: cron # トリガータイプ: cron metadata: timezone: Asia/Tokyo # タイムゾーン start: 0 * * * * # 毎時0分にスケール開始 end: 15 * * * * # 毎時15分にスケール終了 desiredReplicas: "10" # 10までスケールアウト
kubectl apply -f deploy/rabbitmq-cron-scale-object.yaml scaledobject.keda.sh/rabbitmq-consumer-cron configured
これでScaledObjectが作成されました。
例1と同様に、ScaledObjectと共にHPAも作成されるのを確認します。
kubectl get hpa; kubectl get so NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE keda-hpa-rabbitmq-consumer-cron Deployment/rabbitmq-consumer <unknown>/1 (avg) 1 100 0 10s NAME SCALETARGETKIND SCALETARGETNAME TRIGGERS AUTHENTICATION READY ACTIVE AGE rabbitmq-consumer-cron apps/v1.Deployment rabbitmq-consumer cron True False 10s
このあと、指定の開始時間になったあと、ScaledObjectのACTIVE項目がTRUEになり、スケールアウトが徐々に行われていくのが確認できます。
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE keda-hpa-rabbitmq-consumer-cron Deployment/rabbitmq-consumer 2500m/1 (avg) 1 100 4 11m NAME SCALETARGETKIND SCALETARGETNAME TRIGGERS AUTHENTICATION READY ACTIVE AGE rabbitmq-consumer-cron apps/v1.Deployment rabbitmq-consumer cron True True 11m ... NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE keda-hpa-rabbitmq-consumer-cron Deployment/rabbitmq-consumer 1250m/1 (avg) 1 100 8 12m NAME SCALETARGETKIND SCALETARGETNAME TRIGGERS AUTHENTICATION READY ACTIVE AGE rabbitmq-consumer-cron apps/v1.Deployment rabbitmq-consumer cron True True 12m ... 10までスケールアウト NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE keda-hpa-rabbitmq-consumer-cron Deployment/rabbitmq-consumer 100m/1 (avg) 1 100 10 13m NAME SCALETARGETKIND SCALETARGETNAME TRIGGERS AUTHENTICATION READY ACTIVE AGE rabbitmq-consumer-cron apps/v1.Deployment rabbitmq-consumer cron True False 13m
終了時間が過ぎた後、0までスケールアウト
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE keda-hpa-rabbitmq-consumer-cron Deployment/rabbitmq-consumer <unknown>/1 (avg) 1 100 0 17m NAME SCALETARGETKIND SCALETARGETNAME TRIGGERS AUTHENTICATION READY ACTIVE AGE rabbitmq-consumer-cron apps/v1.Deployment rabbitmq-consumer cron True False 17m
KEDAのCronスケジューラーにより、指定の期間中に指定した数のpodになるまでスケールアウトし、終了したら0までスケールインできました。
終わりに
これでKEDAについてのアーキテクチャの説明と、実際に使ってみてどうスケールするかの確認ができました。
今回はRabbitMQのキューと、Cronスケジューラーによるトリガーを試したのですが、他にも公式でサポートされているトリガーが色々あるので、試してみると良いかと思います。
今後さらに開発が進んで安定してくると思うので、個人開発や業務で使う機会があれば試してみたいと思います。